
Altera FPGA的速度没有Xilinx的速度快,错!当然这种非对称的结构,你必须有一定的了解,才可以更好的利用.也就是要遵循:
- 大的数据吞吐通道应该采用横向放置规划!
- 控制通路采用纵向放置规划!
Altera至此以后,一直沿袭这种结构规划.因此,如果你想有效利用好Altera的产品,就应该遵守这个规则.但是要说明的,真正能体现性能的东西,也许就是你意识不到的一种小东西,就是简单的就是最好的.Altera正是凭借这个简单而高效的布局结构实现了今天的王道!昨天说到这里今天继续开始. 又有很多时候没有提Lattice,在1998年的时候,Lattice和Altera同时都有成为PLD霸主地位的意图.什么可以证明呢,那就是谁最先推出可以ISP的宏单元超过1000个的PLD. 当然在这个游戏过程中,Altera有一些变化,他有效的将他的Flex8000的布局结构和他的MAX7000进行结合. 从而实现了在PLD规模扩大的同时可以实现:
- 规模的迅速扩大,可以比肩Xilinx的FPGA
- 局部的快速布线,和ISP,使其在获得规模优势的同时,保持布线延迟的稳定
- 沿用过去MAX7000的适配结构和FPGA的路由,实现两者有效的统一.
Altera在推出他的最大的9560,具有560个宏单元的PLD,登上了无可争议的PLD冠军奖台.
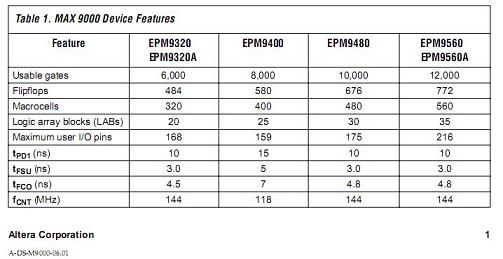
当然有的人要说,Lattice有推出1000个左右,怎么不提呢. 正是因为这点,导致Lattice步入歧途. 实际上,FPGA世界的游戏规则已经改变了.
MAX9000的成功得益于以下的细微结构.这个时候Altera又一次将自己的颗粒度进行了扩容. 有16个宏聚集在一起,在实现更多位的加法,控制,超前进位,大的多选一的应用中,可以将这些模块一次性放入一个LAB,同时在LAB内完成路由. 现在已经露出一种迹象. 大的规模要有,但是速度的需求已经开始了. 所以在FPGA,CPLD的应用中,又有了新的裁判规则,你不仅要够大,还有够快
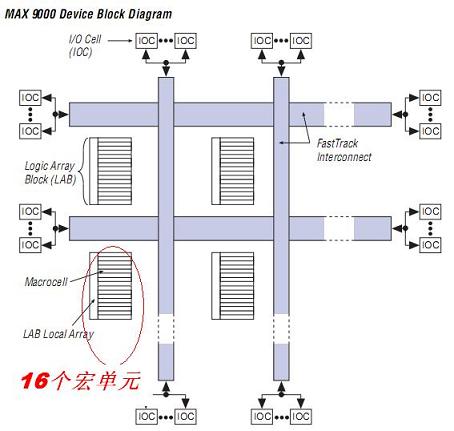
这个时候的异步设计还是非常的多,而且板子上芯片间信号的互联也多起来了,能够有效缩短Tsu已经成为一个重要的话题. 实际上,就是在IOC上要有DFF,来进行快速锁存,同时也为所有进入CPLD的总线信号进行第一次整理. 怎么实现很多的异步设计,看了下面,你就明白了. 第1点,就可以用所有信号的函数输出作为clk,第2点,有效的将没有用完的资源很好借用给其他的宏,来用对称的结构实现非对称的应用!用简单的结构,应变不断的变化.
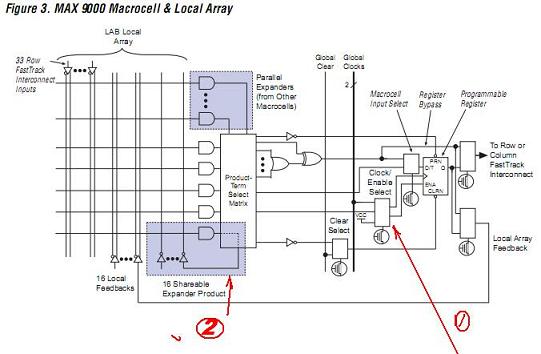
纵观当时其他的PLD,在结构上就落后很多了. 你想,让你和姚明来争篮板球,如果你没有人家的身材,赢他恐怕也是嘴上的功夫了.
这个时代的强者就是---谁有最多的逻辑资源,或者memory,谁就是老大.
上面说到Lattice已经在极力扩大自己的身材,但是他不是靠结构上的改变,而是Lattice收购了Vantis,也就是AMD的一个做PLD的小部门. 当然在当时,AMD的Mach就这样并入了Lattice的家族. 新的问题就出现了. 好比我们现在有人用什么大灵通,小灵通,GSM,CDMA,是有百花齐放的感觉,但是Lattice就像变成了解放前的蒋介石,没有办法很好的用一套工具来统一使用不同的器件. 而且本身Lattice自己当时的工具也是3个独立的工具拼凑在一起的. 那个年代,用过Tango,后者Orcad的人都知道,他们的图形输入是第一名的,但是和MaxplusII比起来,自动识别对象链接,以及和Office 95类似的快捷键,用过Maxplusii的人,让他们转用Viewlogic等workoffice等,简直简直就是抹他们的脖子. 还有当时Lattice的销售团队,总是宣扬他们是最好的PLD,有些人竟然有 "我认为64KROM,就可以应付未来所有的软件需求" 这样的论调,认为PLD必将击败FPGA,事实上,市场的残酷,告诉他们那是个很冷的冬天. 于是他们又一次在2000年左右,如同水淹七军一样的结局,又急忙掉转船头,收购了ORCA,可惜了ORCA是出自Lucent的一条好汉,由于没有良好的软件支撑,使得每个工程师必须像哪吒一样. 对了,怎么会像哪吒? 因为你必须有三头六臂,如果你公司有些产品需要从32个宏单元到2000个LE的FPGA的应用,你就必须学习3种工具来适应它. 你想想,你是不是一定要像哪吒呢!
再次谈结构以及方法学!
这里开始讲些看来与我们主题有点不搭界的东西.
1--两个人相遇,只握1次手
2--三个人相遇,每人都握一次,握3次手
3--4个呢?就是2的结果加3次,6次手
4--5个呢? 10次手.
5--16个呢,.......天,不少于...
PLD就是这样的产物,当逻辑……你会发现,路由的面积都超过了有效的逻辑面积. 而且,越大越糟糕. 可以下载这个简单的PPT来发现一些小问题!
advantagestruc.zip
什么样的数目比较好,对于PLD的宏单元数目
实践是检验真理的唯一标准. 有人说了,256个是最好的结构,为什么呢,不然怎么那么多厂商都是在这个范围呢. 实际上,他是由经济规律决定的,就是当时用256个的宏单元结构的芯片的面积,和他们卖出的价钱,比较符合当时这些上市公司的利润要求,所以.....就以这个最流行了.
但是Altera进行了很好的变通. 中国有句话叫"玄之又玄,妙之又妙",什么是玄? 玄就是变通的意思,也是变得意思. 实际上万事万物都是相通的. 那Altera就像我们的学校一样,每个年级分不同楼层,每个楼层分不同班级,每个班级上不同的课. 但是用行列块的方式,达到既有规模,也有位置相关性. 而且路由的面积也不会大到赚不到钱. 实际上你自己观察,近10年 ,Altera的FPGA的主要框架是没有变化的!
Xilinx 的FPGA结构,实际上,有一个5200系列,很向Altera的Flex6000,但是没有多久这个东西就不见了. 总之,Xilinx的结构属于称为 "孤岛式"结构,就是CLB在中间,路由围着这个孤岛. 在一定的密度的时候 ,这种结构也还是不错的,当然有一个很重要的结构就是,他是全对称的. 就是Xilinx的芯片的逻辑上资源的密集度是上小左右对称的. 这个有好处,但是也有坏处. Altera的呢,是横向资源丰富,纵向资源相对较少,但是,在局部的横向上,又可以进行级联LE,DSP,Carry chain 等等. 好了,给大家举个简单的例子.
孤岛式的结构
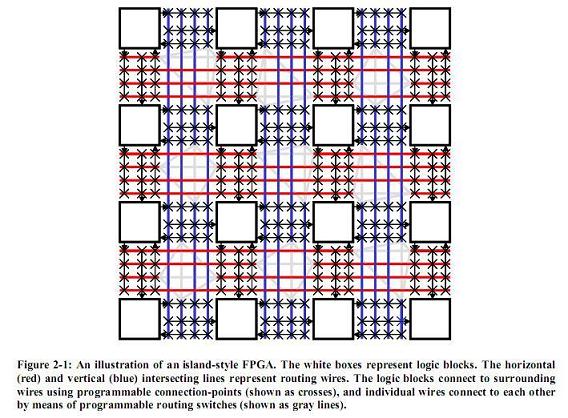
Altera 的类似的结构,但是颗粒度大,从这张图,应该可以看出altera在横向资源是很丰富的. 就是同一行的资源远多于同一列的. 输入输出就更是了. 当然,这个和管脚的封装脚的出位不是绝对一一对应的.

Stratix的出现
在2001年,Altera推出了他们最伟大的产品,Stratix. 当时FPGA的竞争规则又发生了改变
- Altera用TRAM的形式和Xilinx的分布式RAM和blockRAM竞争
- Altera的PLL性能超越对手
- 布通率,利用率,表现突出.
但是上面这三点,都不是决定性的. 这个时候,数据通信对背板走线和背板总线要求已经很高了. 实际上FPGA也摇身变为系统级芯片了.
你不仅要有大的逻辑规模,合理的memory尺寸,相对丰富的时钟资源,还有就是要有高速的Serdes,缺少一项,你都会在系统级的应用中只能是亚军!
刚才说了系统级的应用,已经成了FPGA最残酷的竞争市场. 那么PLD呢,怎么样了,实际上自然总是物竞天择!PLD已经变为这样的几种应用了
- 输入输出的扩展!
- 简单总线或者接口的协议转换
- 对系统级的模块进行配置,或者控制.
- 上电初期的一些管理
就像一个国家的海军一样,PLD已经成为一些简单的驱逐舰,驰骋大洋的,可以跨海作战的,绝对不是这样的产品可以涵盖的. 所以,你今天喝可乐的时候,不会有太多的选择. 偶尔的一些牌子如同过眼烟云,很快就弹出你的视线了.
是的,十年前我的很多朋友,有在Quicklogic,有在Cypress,现在还有一些在不断出产品的公司,当然,只能是剑走偏锋. 做些细分市场还是可以继续的.但是三国鼎立的形式已经是不可撼动的事实了.
北京和深圳的差别?
你到过我们的首都北京吗?到过我们的特区深圳吗?这样打比喻是因为我在深圳和北京都旅游或者工作过.实际上我也只是想借用这两个城市的布局来做个比喻.
北京是比较对称的城市,有东直门,西直门. 有东单,西单等等. 总之,他的布局就像Xilinx,无数个胡同就是像Xilinx围绕在CLB的路由线. 这些资源在Xilinx的数据手册中有:
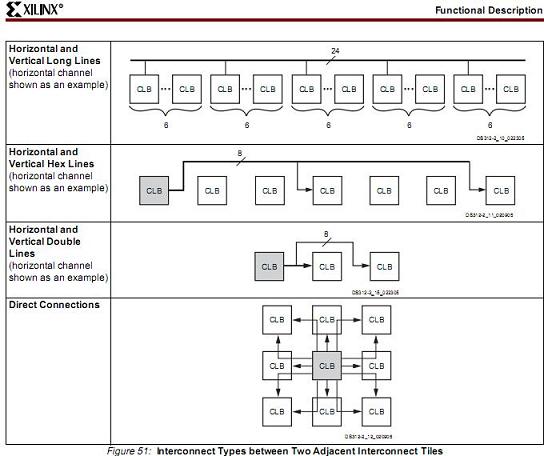
但是这些胡同间的联线并不是十分充足. 特别是到了规模很大的时候.Altera的呢?在深圳的人,如果你不认路,很简单,只要你走到"深南大道,滨河大道,北环大道"上的任意一条,你就可以再从这些大道到你要去的地方. 但是前提是 ,这3条大道的宽度要够. 提示一点,这三条大道也是东西走向比较平行的. 而且整个深圳也是一个东西走向的城市,地下再有一条地铁,在同样资源的情况下,布通率,和平均车速是非常好的. 而北京的地铁,是环形的.资源上不如深圳的利用率高,这里无意于评价城市规划和道路设计. 只是比喻.
Altera的FPGA就是如同深圳的道路,他可以让你从列上很自如的转到宽阔的行上,然后再到达你的目的地. 所以,可以告诉你一个经验.
- Altera FPGA,布通率基本在95%左右,没有太大问题,Stratix最大的产品,有人有99%的布通率
- Lattice的FPGA,规模超过20KLEs,布通效率....有愿意透漏的吗?
- Xilinx,规模越大,有所恶化.
另外,这个地方也有颗粒度大带来的好处. 所以,有些原来看似不精细的地方,却在规则改变后,就变得反而是犀利无比.
运筹学也是很重要的!
经常有这样的情况,大家选择FPGA的时候,就开始翻看每种FPGA的选型手册,然后对资源表. 有的甚至直接说:我这个是10万门的. 你的那个是6万门的,实际上,这些都不是很正确的评估. 如同有人说,我家的房子4室两厅,你家的房子3室1厅双卫生间. 到底哪个更大呢? 到底哪个更节能呢. 厨房热水器之间离得很远又是问题.
所以说,学会正确的评价资源是很重要的. 这个时候还要参照他的结构!!板式的,还是砖混的!!!
可能你还听说过一个使用面积的问题. 实际上,有的房子看起来大,走道,不规则的布局,导致很多的地方都不能用!下面看个例子:
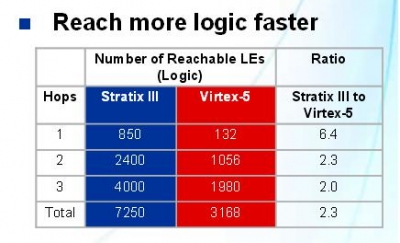
左边的Hops代表跨一步的意思,就是路由转换一次的意思. 这个表什么意思呢. 就是说在S3的路由过程中,每个路由在第一次,就可以覆盖850LEs中的一个,V5是132. 如果你的逻辑,经过4跨,同样的路径覆盖的区域A的是X的2倍. 代表什么呢?
- 编译速度更快,因为概率提高,路由成功率提高
- 布通率更高
- 速度更快!为什么,90nm以后,LE内部延迟已经不如路由延迟的时间长了. 所以经过的路由多,就会严重降低系统速度.
当然还有一些好事者,例如 (http://www.opencores.org) 有很多公开的opencore,大家可以将它们同时尝试放在A,X,L,看谁放的多,放的快,系统延迟更小. 这方便数据就不多说了,可能都成为一门学科都不一定,因为不同的比对都有benchmark的不同标准. 最终我们应该很清楚的看到.
结构真的是很重要,我们能干,也要看是否站在巨人...
不过呢,很多时候,我们的朋友基本上都说: 结构和我无关,我要学好VHDL,我要....codingstyle. 这个设计属于系统工程!
FPGA的真正命门和Know How实际上,能做FPGA的公司太多了,但是能将我们的设计通过算法成功放到这个芯片上,而且算出正确的时间和你的仿真要求的. 就不多了,说的难听点. 有些领域甚至是没有亚军的竞争!选择小规模PLD,那些,不是太重要的问题. 本身就不够养活一票人的产品.
Cyclone III 与 Spartan3 的对决--苹果对苹果?
目前,很多人都基本上对于新的中档设计都会集中在这个系列的竞争中,换言之,在中国目前以成本为导向的第一要求下,实际上中小公司的产品选用80%是集中在这里.
经常有人说,为什么你们的LEs数目相同,价格很不同. 做些解释,一家之言.
- 在今天,尽管是可以编程的器件,还是有不灵活的地方. 例如,你的应用决定你对什么资源敏感
- 不同市场也有不同的关注. 没有哪个东西绝对适合,只能是系列之间互相交叉来完成.
有一点要说,那些所谓我的是多少系统门的比较方式,是典型的大忽悠模式
比较产品有很多benchmark. 这里列举一些. 不全的地方,可以大家补充.
- 工艺
Cyclone III,65nm
Spartan3,90nm
眼前看,90nm是主流工艺,但是未来降价空间在2009年中达到轨点,另外,65nm的功耗不用说,35%的优势轻轻松松. - 设计学
CycloneIII ---LP工艺,有很多人不理解这个,同样的设计采用LP和不采用就很大不同.
Spartan3--没有采用 - 规模
Spartan3,3e,3a,3an,覆盖区域不同,从1K到40KLE左右
CycloneIII: 典型长中长焦距镜头,5K到120K,
40K 以上,基本上Spartan3没有产品,可以用V5,V5定义为Highend,S3定义为Lowercost
无线,DSLAM,医疗,平均规模在25KLE到80KLEs为最多,CycloneIII解决了有无问题 - Memory
这个是CycloneIII的幸运之处,当时可能设计上没有这么大吧.
9K块,总容量绝对平均高出S为30%,块数也同样. Sp3dsp例外,但是他只有两个孩子.定焦镜头.要符合你的品味.
memory多影响到: CPU速度的提高,DSP应用,DUC,DDC,FIR等,级数上可以做更多. 速度高,还可以提高复用. - 乘法器,一个18x18的乘法器,相当于350-450个LEs,当然流水的话要另外算.
- PLL: Altera是模拟的,X是数字的. 恢复性和收敛速度那毫无疑问,地球人都知道模拟的好. A的时钟树更是多
- 布局: 从左到有,基本符合多时钟域交叉,
如: LVDS入,经过第一级FIFO,进行时钟域交叉,或者数据交叉,第一次处理,然后经过中间逻辑加工,参数重加载等,然后进入乘法器,可以级联,然后有通过通用逻辑池进行加工,再次通过FIFO或者RAM来对接下一级.
其他行可以独立构成NiosII等,布局收敛性一流. 我尽量找个照片来显示.
所以不是简单说我的苹果和你的苹果一样. S3只有销价处理才是真正的出路.
如果你知道了结构,你会发现什么呢?
实际上,Altera一直在横向布线资源上浓墨重彩,因此,在Cyclone一代系列的时候,如果你的设计模块放在一个比较长的区域就更加容易跑出好性能.
如: 5行,5列的一个资源放置,不如在一个4行7列的区域中更好发挥性能.
到了CycloneII,可能就是接近1:1.2的样子.
Statix,基本上接近正方形.
其他的你可能需要实验一下. 毕竟这个是动手的科学. 而且,每家FPGA厂商,在关键布线资源方面,都是秘而不宣. 这个也是为什么Synplicity要另嫁豪门的原因!因为自己没有办法得到这些资源. 而综合技术已经被FPGA厂商步步紧逼了!
Cyclone III的巧合.
Cyclone III的诞生,可以说也是有划时代意义的.但是赢得偶然,其中已有些必然.下面来说说这个东西.
前面有人说过Xilinx的V5不错,但是如果说V5和StatixIII带有Serdes的产品同时间面世的话. 作为设计者,可能问题就来了. 太多选择就是难以选择
StratixIII 速度快,布线好,但是没有Serdes
V5速度布线都不错,出来的早,快人一步也是卖点.
但是呢?这两个产品都很贵.
由于Xilinx很重视高端用户,因此他们也认为Spartan3可以解决目前很多需要,这个也对,因此他们计划在45nm左右推出Spartan的升级产品.
Cyclone III,正好赶上高端DSP处理市场的繁荣,以前Xilinx的website上面也有这方面的迹象. 号称Xilinx也是一个DSP的公司. 这个也要得益于其他生态链软件系统的发展,Matlab的simulink,
另外,目前的有线系统中对Memory的需求也非常高,作为有效的缓冲也需要更多的空间.
举例来说,一个Video的应用. 需要一些滤波或者其他的应用,那需要的FIR的Tap数目实际上是可大可小的. 但是以前他们认为逻辑资源的比例太多于DSP的建立资源. 导致很多设计用30万个LE的资源的FPGA,实际上,Logic资源利用在30%左右,而Memory仍旧显得很局促. 还有一个就是用DDR2的设计也有增多的趋势,
还有就是中型设计的比重已经上升很快,就是在3年前,大家很多集中在6000个LE左右的资源. 而紧接着的趋势是200个500个左右的资源和10000个LE资源的迅速两级化. 另外一个增长就是50000个LE左右的区间,而这部分长期以来都是Stratix和v4,v5的传统空间. 可是现在由于memory,mulitiplier的增加,导致系统性能也可以用CycloneIII实现资源换取速度和效率的方案. 因此CycloneIII的资源也能利用低价格来和高端FPGA分一杯羹.
但是CycloneIII尽管有价格优势,逻辑和memory的优势,可是在Serdes的应用上,还是一片空白. 这也是大家觉得他的缺憾所在.
总之,CycloneIII和Spartan3 DSPA系列的推广,已经有一个暗示的信号,就是
以多块,大容量memory,Serdes可选的特点将成为新的中级FPGA市场的标杆了.
为什么Cyclone,或者说Altera的粗颗粒有一定的好处?
大家都知道,Altera的结构可以说看起来是大开大合,实际上是粗中有细.
以前一个LAB有8个LE,大家都可以理解,后来又发展成有10个LE,有16个LEs
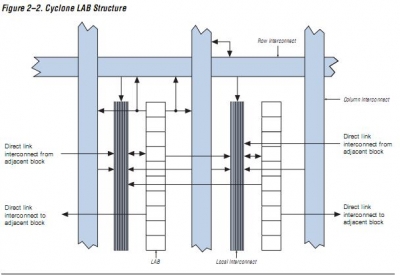
如果你有一个计数器,假定在Cyclone里和Spartan里面跑,Cyclone和Spartan在做8位计数器方面应该是不相上下,但是,当在16位计数器还要跑同样的速度,而且保证路由资源最简单的时候,Cyclone的优势,或者说A家的优势就来了.
大家都知道,计数器就是进位翻转的传递链路是他性能的关键路径,换句话说,16位的计数器,就是两个8位计数器的级联,唯一区别的复杂度就是8位的传递时间如果是8x,那16位的就是16x了. 用另外一种方式来思考:
8位的计数器,在到达FE这个数字的时候,就用一个DFF进行一次隔离,提前一个时钟节拍将进位准备好,这样就将一个16位的计数器的复杂度降低到了8位一个样子. 可是原本Cyclone的LAB就有10个LE,因此为了防止毛刺的问题以及刚才需要一个插入的DFF,就刚好放在一个LAB里面,LAB里面的路由是最快的,而且编译基本不太花时间. 同时也为设计流水线的译码技术,提供两级的DFF延迟,但是这些全部做到了放在一个LAB.
大家回顾一下我们的设计,不就是计数器,加多选一,什么FSM就是那几个玩意来回的组合. 然后中间加流水,再平衡流水寄存器之间的路由. 没有新的发明,只有新的组合. 但是Altera这样的结构就相对来说..哈哈又要吹一下牛皮了.
过去10年FPGA产业的发展和FPGA厂商的挑战?
过去10年,FPGA产业发生了些重要变化,简要3点:
- 逻辑数量超过10年前50倍,
- 存储容量超过100倍
- Serdes速度接近10G(Xilinx6.5G)
- 消耗功耗只提高10倍多些.
===============================
- 编译算法和综合算法的提高
- 和结构结合的物理综合
- 编译平台多CPU的支持,例如4核CPU的PC
- 递增编译和编译约束的更好支持





